为什么 DeepSeek 大规模部署很便宜,本地很贵
为什么 DeepSeek 大规模部署很便宜,本地很贵为什么 DeepSeek-V3 据说在大规模服务时快速且便宜,但本地运行时却太慢且昂贵?为什么有些 AI 模型响应很慢,但一旦开始运行就变得很快?
来自主题: AI技术研报
10216 点击 2025-07-08 11:14
 搜索
搜索
为什么 DeepSeek-V3 据说在大规模服务时快速且便宜,但本地运行时却太慢且昂贵?为什么有些 AI 模型响应很慢,但一旦开始运行就变得很快?

没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。
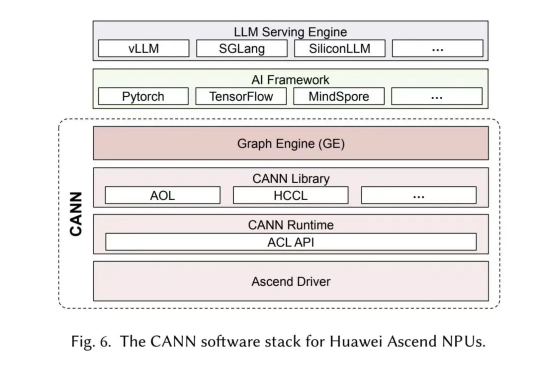
今年 4 月,围绕“华为芯片效率是否超越国际主流 AI 芯片和架构”的问题,网上曾引发一场激烈争论。

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
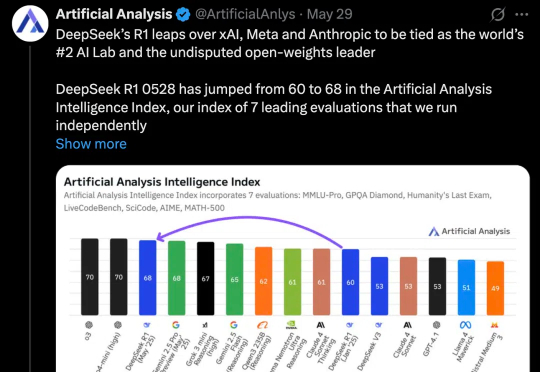
几天前,没有预热,没有发布会,DeepSeek 低调上传了 DeepSeek R1(0528)的更新。
DeepSeek 猝不及防地更新了,不是 R2,而是 R1 v2。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……

在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

当技术范式重构,强者也不得不重新起跑。

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。